

-
通过遥感手段提取大区域(国家级、省级)植被覆盖信息多采用具有高时间分辨率、宽视域、对存储介质要求相对较低、获取方式更便捷的中低分辨率遥感影像, 如AVHRR、MODIS等。计算机自动提取方法以基于像元的非监督分类方法和监督分类方法为主, 非监督分类方法得到的分类结果精度相对较低, 并依赖专家经验进行分类后的类型组合, 如GLC2000[1]、DISCover全球1 km土地覆盖产品等[2]; 监督分类方法得到的分类结果精度相对较高, 其中选择具有代表性的样本数据比修改分类算法本身对分类结果的影响更为重要。
当前, 国内外常采用以下方法对遥感影像监督分类的植被类型样本进行采集: (1)参考资料数据, 依据专家经验, 借助更高分辨率遥感影像的解译结果或者植被图、土地利用图等先验数据。Darren Pouliot等[3]采用MODIS数据监测加拿大森林变化, 参考了水文、高程、公路网等数据的同时, 部分区域借鉴Google数据和TM等更高分辨率数据采样; Igor Klein等[4]采用MODIS数据对中亚土地覆盖变化检测, 主要依据TM影像解译结果进行采样; 张永红等[5]用MODIS数据生成全国土地覆盖产品, 辅助土地利用图、植被图和局部区域的TM、SPOT更高分辨率影像数据获得训练样本; 左玉珊等[6]基于MODIS影像的京津冀区域土地覆被分类, 辅助京津冀区域土地利用资料、TM遥感影像、DEM高程数据; 范应龙等[7]基于TM影像通过决策树分类提取热带森林覆盖变化信息, 训练样本采用柬埔寨国家林业局野外调查数据; 张雨等[8]基于MODIS数据实现的辽宁省土地利用分类, 通过分析辽宁省林地更新数据和一类样点数据选取训练样本。(2)结合调查数据的样本采集方法。刘华等[9]基于四个时相的TM影像, 根据外业调查信息以及研究区植被图、湿地分布图获取的样点数据, 提取湿地信息; 陈巧等[10]基于两期TM影像, 参照研究区森林资源分布图、土地利用图以及外业调查数据进行训练样区选择, 通过监督分类结果监测天保区植被变化; Kun Jia等[11]采用MODIS时序数据与TM影像融合提取了中国北部5个县的森林覆盖信息, 训练样本的选取借助于样地调查和Google数据; 竞霞等[12]采用两期TM影像对密云山区植被分类研究, 采用野外调查获得的植被类型信息选取训练样本。
从国内外研究可知, 遥感影像监督分类的样本选取方式大多凭借专业经验、资料数据或结合调查数据等目视判读采样, 有关大区域遥感快速采样方法的类似研究比较少。本研究利用遥感影像的宏观性, 基于植被分类资料数据, 依据实验区域遥感影像及衍生影像本身特点, 实现了大区域样本快速提取。本实验的创新体现在将实验区资料数据与遥感影像相结合, 依据统计分析实现植被样本的快速提取。降低遥感监督分类采样过程中的人为干预, 提高大区域采样效率, 增强样本的客观性。实验结果可以为快速提取实验区植被覆盖信息, 提供可靠的样本数据。
HTML
-
本实验采用2001年23期时序MODIS/Terra Vegetation Indices 16-Day L3 Global 250m SIN Grid(简称MODIS13Q1)数据, 每期间隔16天, 属于陆地专题产品, 是MODIS的L3级科学数据集产品之一。MODIS13Q1产品原始文件包含多个数据层, 实验选取第一层归一化植被指数(Normalized Difference Vegetation Index, 简称NDVI)数据文件[13]。
本实验采用2001年1∶100万中国植被图矢量数据, 可提供实验区植被分布信息; 中国植被区划矢量数据提供实验区范围; 2000年中国土地覆盖1km栅格数据[14-15](简称WESTDC), 可提供实验区非植被分布信息。其中, WESTDC数据来源于国家自然科学基金委员会“中国西部环境与生态科学数据中心”(http://westdc.westgis.ac.cn)), 该数据借鉴IGBP分类系统, 在保持了中国土地利用数据的总体精度的同时, 补充了中国植被图中对植被类型及植被季相的信息, 更新了中国湿地图, 增加了中国冰川图, 融合了MODIS 2001年土地覆盖产品。
以上矢量、栅格数据均具有空间坐标信息, 且经过影像配准, 精度限制在一个像元内。
-
本研究选取寒温带针叶林区域作为实验区, 实验区处于127°20′E以西, 49°20 ′N以北的大兴安岭北部及其支脉伊勒呼里山地, 总面积约为211 600 km2。植被覆盖率高, 地带性植被为兴安落叶松林, 有少量灌木植被, 是我国重要的木材产地。由于该区域的寒温带气候, 形成永久冻土层, 水分下渗困难, 形成零星水体, 地表积水使湿地广泛发育, 其中草本沼泽分布在海拔900 m以下地带。该区域平坦谷地区域有农业分布但农业不发达。
1.1. 实验数据
1.2. 实验区概况
-
首先, 通过ARCGIS软件在寒温带针叶林区域内随机布点, 生成的样点具有中国植被区划文件的空间信息, 每个样点在实验影像上体现为一个像素, 代表实际地物250 m×250 m的样地范围。参考1∶100万中国植被图和中国土地覆盖数据, 分别赋予植被类样点的类型属性, 包括: 乔木、草地、湿地、灌木、农田; 非植被类样点的类型属性, 包括: 建筑物和水体。并对各类样本的初始可分离性进行计算。
然后, 对实验区2001年23期MODIS时序NDVI影像数据产品, 依据不同植被类型的NDVI特征向量不同, 采用非监督分类迭代算法[15]得到时序NDVI数据波段的集群聚类信息。结合该非监督分类结果, 依据矢、栅数据的空间特征, 将非监督分类的类型信息作为各类样本中的样点属性进行关联, 统计各类样本包含的非监督分类类型和样点个数(j, NRi), 并将对应类型的样点比例作为权重值(PRi)。权重越大则越能够代表该样本类型, 权重越小则越可能是该类样本中的非纯样点, 按照权重大小降序排列样点(Descend(PRi))并计算累积百分比(PRacc)。其中, j为样点个数、R为植被类型、i为非监督分类类型。
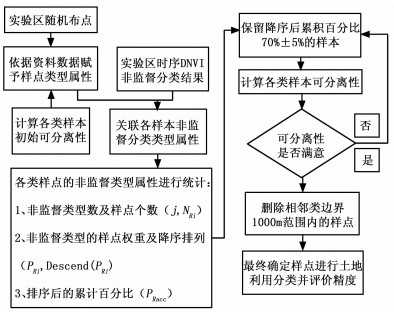
大区域植被样本快速提取总体思路, 如图 1所示:

Figure 1. Methodological framework of quick sampling in large area
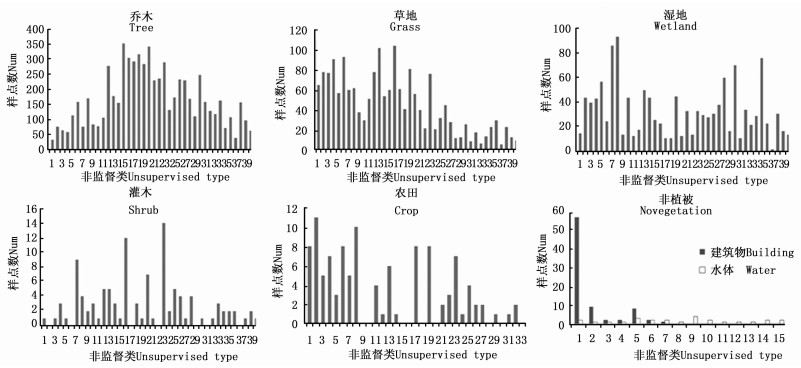
将初始7类样本对应的非监督分类的结果, 依据每一类样本中包含的非监督分类类型及样点个数, 绘制分布直方图, 如图 2所示:

Figure 2. Histogram of samplings with unsupervised feature
统计结果表明, 研究区域内植被以乔木、草地、湿地类为主, 灌木、农田较少。该区域建筑物在非监督分类中特征明显, 与其他地物很好的区分。水体零星分布, 样点较少。本研究以植被类样本纯化提取为主, 建筑物和水体为非植被类型样本不予讨论。
依据像元类型权重信息和空间信息剔除各类样本中不合要求的样点, 进行样本纯化[16]。保留权重大的更有代表性的样点, 剔除掉权重比例小于2.0%的样点, 剩余的样点累积百分比为70%±5%, 在此样点比例范围内再结合可分离性指标进行样点的取舍。
对保留样点的非监督分类类型、权重、累积百分比进行统计, 如表 1所示:
类型
Type乔木
Tree草地
Grass湿地
Wetland灌木
Shrub农田
Crop1 5.31 5.83 7.00 12.96 10.00 2 5.15 5.72 6.48 11.11 9.09 3 4.77 5.21 5.72 8.33 7.27 4 4.58 5.09 5.27 6.48 7.27 5 4.40 4.53 4.52 4.63 7.27 6 4.35 4.36 4.29 4.63 7.27 7 4.26 4.36 3.77 4.63 6.36 8 4.19 4.30 3.39 3.70 6.36 9 3.72 4.24 3.31 3.70 5.45 10 3.55 3.62 3.31 3.70 11 3.50 3.45 3.31 2.78 12 3.46 3.40 3.24 2.78 13 3.46 3.34 3.01 14 2.66 3.34 2.86 15 2.60 3.17 2.56 16 2.54 3.11 2.48 17 2.53 2.48 18 2.44 19 2.38 20 2.36 总计Total 72.21 67.06 67.00 69.44 66.36 Table 1. Unsupervised types with weight factor and accumulative percent of purified points
% 最后, 从空间信息上判断, 地类边界过渡区域的像元往往都是混合的非纯像元, 因此剔除相邻类型边界1 000 m范围内过渡区域内的样点。
-
采用Jeffries-Matusita距离(以下简称J-M距离)和转换分离度(Transformed Divergence, 以下简称T-D)作为测度指标来检测所选取的任意两个类别训练样本之间的分离程度。可分离性指标(Separability)取两者中较小值, 即Separability=Min(J-M, T-D)。可分离性指标值为0~2.0, 大于1.9说明样本之间可分离性好, 1.9~1.8属于合格样本, 小于1.8需要重新选择样本, 小于1考虑将两类样本合成一类样本。
如表 2所示, 对于可分离性指标小于1.8的样本, 认为样本中混有其他类型样点, 因此, 删除此类样本中权重比例小的干扰样点, 再计算可分离性指标。反复操作以上过程, 并比较分析可分离性指标, 决定样点取舍。最终得到具有代表性的植被类型样本。
地类Types 纯化Purify 乔木Tree 灌木Shrub 草地Grass 湿地Wetland 灌木Shrub 前Before 1.631 后After 1.992 草地Grass 前Before 0.901 1.488 后After 1.970 1.997 湿地Wetland 前Before 1.049 1.607 0.860 后After 1.933 1.998 1.780 农田Crop 前Before 1.915 1.959 1.741 1.887 后After 1.998 2.000 1.938 1.995 Table 2. Separabilities of purified and unpurified samples
对比纯化前后的结果可以看出纯化后各类样本的可分离性指标提高到1.9以上, 可分离性良好。只有湿地和草地类型可分离性指标值为1.78, 认为湿地区域覆盖的植被和草地区域覆盖的植被多为草本植物, 受实验中特征影像制约辨识度不高。
-
对比2001年MODIS全年数据的第33天、第145天、第257天、第353天的影像, 纯化前后的各植被样本的平均值和标准差, 如表 3所示。
地类
Types纯化
Purify灰度平均值Mean gray value 灰度标准差Gray Stdev. 像元数
Pixel amount保留百分比
Retain percent/%B33d B145d B257d B353d B33d B145d B257d B353d 乔木Tree 前Before 1 693.5 7 509.6 5 776.4 2 294.4 1 957.3 1 038.6 852.6 1 832.5 6 685 后After 1 424.1 7 677.8 5 879.9 2 229.0 1 640.6 769.1 812.4 1 706.8 3 489 52.19 灌木Shrub 前Before 1 406.1 7 299.2 5 879.9 2 229.0 1 510.1 1 128.7 687.8 1 694.7 108 后After 861.2 7 364.6 4 877.4 1 939.8 753.8 1 080.3 627.8 1 193.0 31 28.70 草地Grass 前Before 960.0 6 709.1 5 257.3 1 896.2 1 391.8 1 459.9 928.3 1 653.1 1 767 后After 337.5 5 375.8 4 692.7 1 207.7 468.5 1 340.4 754.2 1 106.7 409 23.15 湿地Wetland 前Before 1 732.6 6 788.4 5 441.0 2 348.7 1 845.6 1 410.5 854.9 1 881.0 1 328 后After 1 004.6 5 865.5 5 119.6 1 842.5 1 063.5 1 306.3 804.9 1 574.2 212 15.96 农田Crop 前Before 590.1 6 300.5 5 369.6 1 694.0 1 167.8 1 659.6 1 197.2 1 639.9 110 后After 268.3 5 508.8 5 225.2 1 190.6 479.3 1 374.9 946.0 968.3 31 28.18 Table 3. Mean and Stdev. values of purified and unpurified samples
通过对比4个时相影像的统计结果可知, 纯化前后平均值的变化无显著规律, 纯化后的样本标准差大多缩小。纯化后的样本数据的分布曲线变窄, 重叠变小, 可分性增大, 更易于类型间的区分。
-
中国植被图表明实验区植被覆盖以乔木、草地和湿地为主。植被覆盖率为乔木67.40%、草地18.04%和湿地12.48%。灌木0.97%, 农田1.08%两类植被在实验区域较少分布。
为验证纯化后样本的空间分布状况, 统计各植被样本在中国土地覆盖图上分布的混淆矩阵, 如表 3、4所示。
地类
Types乔木Tree 草地Grass 湿地Wetland 样点总数
Total样点数Num. 百分比Percent/% 样点数Num. 百分比Percent/% 样点数Num. 百分比Percent/% 乔木Tree 3 054 87.53 16 3.91 16 7.55 3 086 草地Grass 377 10.81 370 90.46 130 61.32 877 湿地Wetland 51 1.46 20 4.89 62 29.25 133 其他Other 7 0.20 3 0.73 3 1.42 13 总计Total 3 489 100.00 409 100.00 212 100.00 4 110 Table 4. Compared the distribution of high coverage vegetation samples with WESTDC by confusion matrix
表 4中乔木、草地纯化后样本与中国土地覆盖类型中相应植被类型的空间分布基本一致, 精确程度达到87.53%和90.46%。湿地与草地均以草本植被覆盖为主, 两种植被类型在实验影像上不易区分, 因此样本代表性相对较差。乔木、草地、湿地三者空间分布的总体精确程度为84.82%。
表 5中农田样本与中国土地覆盖类型中相应植被类型的空间分布基本一致, 精确程度达到90.32%, 由于实验区灌木分布极少, 覆盖率仅为0.97%, 同时中国土地覆盖图与中国植被图中灌木类空间分布不一致, 导致灌木样本以WESTDC为参考的空间分布状况精确程度较低。但灌木样本可分离性指标高于1.9, 不影响与其他类型的区分, 故认为灌木样本基本不会影响到各类植被覆盖信息的表达。
地类
Types农田Crop 灌木Shrub 样点总数
Total样点数
Num.百分比
Percent/%样点数
Num.百分比
Percent/%农田Crop 28 90.32 1 3.23 29 灌木Shrub 0 0.00 2 6.45 2 其他Other 3 9.68 28 90.32 31 总计Total 31 100.00 31 100.00 62 Table 5. Compared the distribution of less coverage vegetation samples with WESTDC by confusion matrix
实验样本中的植被空间分布与中国土地覆盖图中植被的空间分布相似度超过80%, 因此认为纯化后的样本在该区域具有代表性。
-
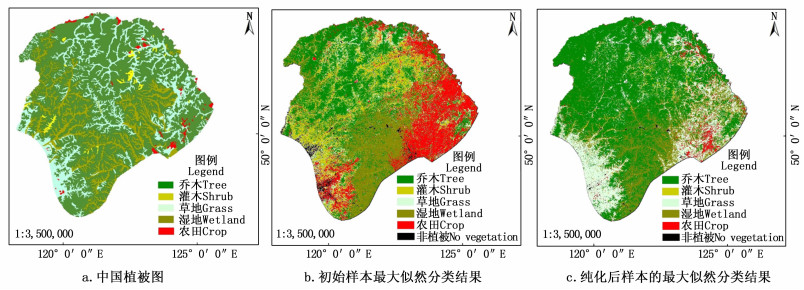
将纯化前后的样本, 分别输入最大似然分类器, 得到实验区域的分类结果, 对比中国植被图图 3(a)中的植被分布, 如图 3所示。

Figure 3. Comparisons of classification results with (a) (b) (c)
验证样点在中国植被图和中国土地覆盖图中植被类型相同的区域随机选取。纯化后样本的最大似然分类结果图 3(c), 总体精度为76.78%;相比未经过纯化的初始样本最大似然分类结果图 3(b), 总体精度44.26%, 提高了32.52%。
由于特征影像、分类器选择会对分类精度造成影响, 验证数据本身也与真实地物存在一定的精度局限性等, 以上因素都可能降低实验影像最终分类结果的精度。因此, 在三者相同的情况下, 纯化后的样本分类结果精度较大提高, 纯化后样本的分类结果与中国植被图中植被分布的总体趋势能够达到基本一致, 认为采样方法是可行的。
3.1. 纯化前后样点可分离性比较
3.2. 初始样点与纯化后样点的平均值、标准差比较
3.3. 纯化后的植被样本结果分析
3.3.1. 纯化后的植被样本精度分析
3.3.2. 纯化后的植被样本分类结果分析
-
(1) 以遥感监督分类方法快速精准的提取大区域植被覆盖信息为研究背景, 本研究结合专家经验和实验数据同质特征向量的聚类信息, 采用统计分析的方法, 实现了针对宏观大区域遥感影像快速提取植被样本的方法。
(2) 实验方法增强了样本的可分离性、缩小了样本标准差, 经验证纯化后样本对实验区域的植被覆盖信息具有代表性, 采样方法可行。所得样本具有实验影像时效特征, 用于遥感监督分类可以缩短大区域植被变化监测时间间隔。
(3) 实验节省了大区域植被类型调查耗费的人力物力资源和时间, 避免了引入多源数据造成的数据冗余和误差影响, 提高了采样效率。
 DownLoad:
DownLoad: