

-
森林规划问题往往具有明显的非线性、非连续性以及非凸性等特征,研究人员采用的求解技术包括传统的数学优化(如线性规划和混合整数规划)和启发式算法两大类。实践表明,数学优化技术已不适用于当今大规模的、复杂的森林规划问题,特别是当规划模型中含有空间约束条件时。启发式算法已被广泛应用于一系列的森林规划问题,如控制最大或平均的连续皆伐面积[1]、降低森林景观[2]或野生动物生境的破碎度[3]等。当前,林业领域中最常用的启发式算法包括:模拟退火算法[4]、门槛接受算法[5]、禁忌搜索算法[6]以及遗传搜索算法[7]等,但现阶段这些方法在我国林业领域中的应用还鲜有报道,仅陈伯望等[8]、曹旭鹏等[9]以及吴承桢等[10]有所涉及,但还仅限于非空间的森林规划问题。
模拟退火算法是对高温加热物体降温过程的模拟,其思想最早由Metropolis在1953年提出[11]。Kirkpatrick等[12]则于1983年首次将其应用于组合优化问题中。1993年,Lockwood等[13]首次将其应用于林业领域,他们解决了一个具有连续收获面积、绿量约束和均衡收获约束的森林空间收获安排问题。此后,作为一种有效的搜索算法,模拟退火在国外的林业领域相关规划问题中得到了广泛应用,如Öhman等[14]建立了包含2 600个林分的森林空间聚集采伐收获模型,结果表明经营措施的空间约束对规划周期内木材净收益的影响相对较小;VanDeusen[15]建立了能够实现森林景观空间优化配置的规划模型,该模型有利于野生动物生境斑块质量和连通性的提高;Bettinger等[16]则建立了基于野生动物生境质量指数的多目标规划模型。但该方法在我国森林经营规划研究中的应用还相对较少,陈伯望等[17]比较了线性规划、模拟退火和遗传算法在森林可持续经营中的应用效果,结果表明当林分数量较多时应优先采用后两种算法;陈伯望等[8]进一步以德国北部挪威云杉(Picea abies(L.) Karst.)林为例,探讨了多种管理策略对森林可持续经营的影响;吴承桢等[10]则建立了多约束条件下的森林造林规划问题。然而,上述研究均未详细报道模拟退火算法不同参数及其组合对规划结果可能造成的影响。
多数启发式算法的性能均对参数取值具有较高的敏感性,即当使用的参数不合理时,算法产生的目标解与该规划问题的实际最优解可能存在较大差异,同时也会严重影响不同启发式算法性能比较的研究结果。因此,在采用启发式算法解决实际的森林规划问题时,应当慎重选择和评估其使用参数对规划结果的影响。现阶段,在林业领域中已有部分学者提出了一些方法来消弱或定量评估这些算法的参数效应,如Bettinger等[16]和Strimbu等[18]均采用传统的试错法(trial-and-error)研究了不同算法的最优参数组合及其对规划结果的影响;Falcã等[19]则在1 300个目标解的基础上,采用极值估计理论实现了最优参数选取;Pukkala等[20]采用Hooke & Jeeves方法实现了多种启发式算法(包括模拟退火算法、门槛接受算法和禁忌搜索算法)参数的自动化估计。这些研究成果均表明参数对森林规划结果具有重要影响,但需要强调的是这种参数效应实际上是很难通过实验来模拟的,特别是同时存在多个参数相互影响的情况下(如模拟退火算法)。因此,研究和掌握启发式算法的参数设置规律及技巧,已经成为当前森林经营规划研究领域的重点和难点。
为此,本研究以模拟退火算法为例,探讨参数设置对森林空间规划问题目标解质量的影响。规划模型以10个5年规划分期内的最大化木材收获为基本目标,同时满足均衡收获和最大连续采伐面积约束。模拟的5个森林数据集共包括3 30081 600个0-1型决策变量。基于上述问题,本研究将重点探讨如下科学问题:1)模拟退火算法的目标函数值是否受参数取值的影响;2)模拟退火算法最优参数值是否受规划问题规模的影响;3)模拟退火算法的求解效率是否与规划问题的规模有关。
HTML
-
本研究创建了5个不同规模的栅格数据集,以代表 5种不同的森林规划问题。这些数据集分别包括400(林分A;20行×20列)、1 600(林分B;40行×40列)、3 600(林分C;60行×60列)、6 400(林分D;80行×80列)和10 000(林分E;100行×100列)个林分,每个林分的面积均假设为10 hm2。为减少林分中其他因素(如立地、树种组成、林分密度等)的干扰,本研究借鉴控制实验的相关方法,即只将林分的年龄设置为随机因素,而使其他变量(如林分密度、立地等)保持不变。模拟的林分年龄均匀分布在050 a。各林分的潜在收获以戎建涛等[23]建立的东北地区长白落叶松(Larix olgensis Henry)人工林蓄积生长模型为基础。在所有的模拟森林中,本研究所考虑的经营活动仅包含两种,即皆伐与不采伐。需要特别指出的是,虽然栅格模拟数据可能与真实林分存在较大差距,但该类数据可避免复杂林分特征和空间关系等因素的干扰,从而有利于实施一个精确的控制实验。因此,该类数据已被众多学者广泛应用于林业领域中相关算法的比较研究[21]。
-
为评估模拟退火算法不同邻域搜索技术对参数的敏感性,本研究采用一个经典的森林空间收获模型。该模型以最大化木材收获为目标,主要包含均衡收获和邻接限制等约束条件。模拟周期由10个5年规划分期组成,即规划周期为50 a,分周期为5 a。根据Johnson和Scheurman定义,该模型属于典型的模型Ⅰ形式[22]:
满足:
式中:T:规划分期数;N:林分数量;i:任意林分;t:任意规划分期;Ai:林分i的面积,单位hm2; Ht:第t分期的总收获蓄积; Vit:林分i在第t分期的可收获蓄积,单位m3·hm-2;Blt:允许收获蓄积在不同规划分期波动的最低下限;Bht:允许收获蓄积在不同规划分期波动的最高上限;Ni:林分i的1-阶邻域集合;Si:林分i的所有2-阶邻域集合;Umax:允许的最大连续收获面积;Ageit:林分i在第t分期的年龄;AgeT:允许收获的最低年龄;Xit:0-1变量,如果林分i在第t分期被安排采伐,则Xit =1;否则,Xit =0;k:林分i的邻接林分,即1-阶邻域;以及邻接于所有1-阶邻域的林分,即2-阶林分,呈无限递归状[23]。
上述方程中,式(1)表示本研究的目标函数,即实现规划周期内的最大化木材收获;式(2)用于计算各规划分期的木材总收获量;式(3)和式(4)表示木材的均衡收获约束,即将不同分期的收获蓄积限制在一定的范围内;式(5)确保最大的连续收获面积不被违背,该约束采用Murray提供的面积限制模型[23],可在空间上避免过大面积皆伐迹地的产生;式(6)为最小收获年龄约束,本研究将其设置为31 a,即林分年龄应达到近熟林或以上;式(7)为资源约束,即要求每个林分在整个规划周期内最多只允许被采伐1次;式(8)表示所有的决策变量均为0-1型,即同一林分不允许被不同的经营方式分割。根据上述规划模型,本研究所模拟的5个森林数据集最终包含3 300~81 600个0-1型决策变量。
-
模拟退火算法来源于对热力学中高温加热物体动态降温过程的仿真模拟[11]。对于具体森林规划问题,算法首先给每个林分以随机的方式指定采伐时间和措施从而产生初始解(S)。然后,在此基础上通过随机方式选择某个林分,接着同样以随机的方式调整该林分的采伐时间和方式而产生当前解的邻域解,即新解S’。之后,算法依次检验该新解的可行性与可接受性,基于检测结果执行以下过程:1)如果新解S’为不可行解(即违背了约束条件),则算法返回前一个可行解,并且通过随机方式产生下一个新解S’;2)如果新解S’为可行解(即满足所有约束条件),同时该解的目标函数值大于当前过程的最优解S*,则将该新解作为当前解S和最优解S*;3)如果新解S’的目标函数值小于当前最优解S*,则根据概率p=Exp((f(S’)-f(S*))/T)接受恶化解, 其中T为当前温度, f ()为目标函数的计算公式。算法一直重复此过程,直到收敛为止。模拟退火算法主要参数包括初始解数量(N)、初始温度(T)、冷却速率(r)以及每温度下的交互次数(nrep),森林经营决策人员可通过对这4项参数的调整来影响算法搜索进程[20]。
-
Pukkala和Heinonen指出启发式算法对参数具有高度的敏感性,不恰当的参数设置不仅影响森林规划结果的实际应用,也会对不同启发式算法性能比较的研究产生显著影响[20]。因此,为减小参数设置对启发式算法求解效率的影响,本研究对模拟退火算法中的初始温度、冷却速率、每温度下交互次数以及初始解数量进行了一系列测试。在现有相关研究结论的支持下[16, 19-20],每个测试参数设置了10个不同的等级(表 1)。对于终止温度,根据相关学者研究结果,将其始终设置为10 [19-20]。理论上,由不同参数随机组合所形成的测试空间高达104(即10 000种情况),这无疑是一个巨大的工作量。因此本研究采用Hooke & Jeeves提供的方法[20],即每次只对一个参数做微小的调整而保持其他参数不变。该方法等同于计算每个参数的边际效益递减曲线,也即1-阶倒数。所采用的基准参数集为:初始温度=106,冷却速率=0.95,每温度下交互次数=600,初始解数量=600。
参数Parameters 等级Level 1 2 3 4 5 6 7 8 9 10 初始温度Initial temperature /106 0.001 0.01 0.05 0.1 0.5 1 2 3 4 5 降温速率Cooling rate 0.7 0.75 0.8 0.85 0.9 0.95 0.975 0.99 0.995 0.999 初始解数量Number of initial solutions 100 200 300 400 500 600 700 800 900 1 000 每温度下重复次Number of iterations per temperature 100 200 300 400 500 600 700 800 900 1 000 Table 1. The tested parameters dataset of simulated annealing
对参数敏感性的测试,采用Bettinger等[16]、Falcã等[19]提供的方法,即试错法(trail-and-error)。由于模拟退火算法在新解的产生及接受过程中均采用了随机策略,因此不同林分及参数级别的组合均模拟20次,以其统计值(如平均值、标准差等)作为评估依据,因此共计4 000个目标解(即20次模拟×10级别×4个参数×5个林分)被产生。模拟程序采用Microsoft Visual Basic 6.0编程实现,优化过程采用安装有2.6 GHz Core i5处理器和Windows 7操作系统的个人笔记本电脑完成,所有目标解均共耗时约330 h。
现阶段已有多种方法可用于评估启发式算法目标解的质量,但其中基于规划问题的“宽松”化混合整数规划(MIP)是其中一种最常用的技术[16]。“宽松”表示忽略所研究规划问题中的邻接约束条件(即式(7)),以MIP的优化结果作为真实规划问题目标函数值的上限。因此,包含了3 300~81 600个决策变量的混合整数优化模型也被建立,以用于评估模拟退火算法3种不同搜索策略的求解效率。该MIP问题的求解采用Lingo14.0软件实现[25]。求解过程首先采用Lingo14.0软件中的默认参数,但发现模拟过程在持续24 h后仍未获得最优解。在经过多次尝试模拟后,本研究允许的最大模拟次数为108次,最终每个模拟耗时约0.45~10 h。模拟退火算法求解效率的评价采用如下公式:
式中:RE为模拟退火算法的求解效率;OBJSA为模拟退火算法获得的目标函数值;OBJMIP为混合整数规划方法获得的目标函数值。同时,因模拟退火算法仅能够提供规划问题的满意解而非最优解,因此该类算法提供满意解的概率也是森林经营决策人员关心的主要问题。为此,将模拟退火算法800次随机模拟中目标函数值介于MIP提供的目标函数值10%以内的数量定义为模拟退火算法获得满意解的概率(PN),其用公式表示为:
式中:d表示模拟退火算法的第d个目标解; D为某个规划问题目标解的总数量,本研究中每个林分包括800个目标解; fd表示第d个模拟退火算法目标解是否为满意解,用式(10)计算;显然如果其是满意解,则fd=1;否则,fd=0;OBJd为模拟退火算法第d个目标解的目标函数值; OBJMIP为混合整数规划算法的目标函数值。
1.1. 研究数据
1.2. 规划模型
1.3. 模拟退火算法
1.4. 测试参数
-
根据上述方法,本研究分别不同参数、不同级别以及不同林分整理了共计4 000个目标解所对应的收获蓄积和优化时间(即算法首次达到最大值的时间),结果如表 2和表 3所示。统计分析表明模拟退火算法获得的目标函数值的变异系数仅在0.18%~14.95%间波动,验证了模拟退火算法的随机属性。相关研究结果将按以下顺序逐一描述:a)特定林分的参数敏感性分析;b)规划问题规模对最优参数取值的影响;c)规划问题规模对模拟退火算法求解效率的影响。
106 m3 N 林分数量Number of management units nrep 林分数量Number of management units r 林分数量Number of management units T 林分数量Number of management units 400 1 600 3 600 6 400 10 000 400 1 600 3 600 6 400 10 000 400 1 600 3 600 6 400 10 000 400 1 600 3 600 6 400 10 000 100 0.617 2.382 5.442 9.674 15.649 100 0.613 2.552 6.376 10.986 16.217 0.700 0.615 2.578 6.132 10.719 15.815 0.001 0.759 3.095 6.973 12.013 18.360 200 0.628 2.408 5.373 9.914 16.500 200 0.621 2.440 5.920 10.848 17.559 0.750 0.616 2.496 6.326 10.969 16.420 0.010 0.654 2.603 6.300 11.527 18.439 300 0.627 2.346 5.420 9.578 16.108 300 0.624 2.339 5.437 10.075 17.594 0.800 0.620 2.402 6.199 11.286 16.628 0.050 0.626 2.429 5.820 11.020 18.234 400 0.631 2.361 5.501 9.468 16.115 400 0.642 2.403 5.252 9.749 18.387 0.850 0.614 2.382 6.032 11.012 17.463 0.100 0.625 2.447 5.867 10.629 18.651 500 0.632 2.382 5.455 9.450 16.860 500 0.638 2.360 5.458 9.931 16.079 0.900 0.622 2.318 5.955 10.437 17.251 0.500 0.631 2.371 5.429 10.273 16.190 600 0.628 2.346 5.504 9.723 15.565 600 0.628 2.346 5.504 9.723 15.565 0.950 0.628 2.346 5.504 9.723 15.565 1.000 0.628 2.346 5.504 9.723 15.565 700 0.628 2.345 5.465 9.605 16.471 700 0.634 2.351 5.289 9.707 16.458 0.975 0.640 2.359 5.231 9.636 15.216 2.000 0.629 2.355 5.330 9.611 16.466 800 0.625 2.400 5.276 9.790 16.117 800 0.632 2.404 5.272 9.646 14.601 0.990 0.637 2.366 5.341 9.118 14.204 3.000 0.625 2.312 5.316 9.580 15.580 900 0.629 2.334 5.215 10.257 16.138 900 0.629 2.389 5.393 9.444 15.754 0.995 0.640 2.364 5.274 9.156 14.707 4.000 0.633 2.463 5.421 9.497 14.638 1 000 0.626 2.414 5.335 9.652 15.559 1000 0.628 2.408 5.323 9.334 14.835 0.999 0.641 2.405 5.286 9.219 14.307 5.000 0.624 2.425 5.291 9.411 15.574 N表示初始解数量; nrep表示每温度下重复次数; r表示降温速率; T表示初始温度(× 106); 下同。N represents the number of initial solutions, nrep represents the number of iterations per temperature; r represents the cooling rate, T represents the initial temperature (× 106); The same below. Table 2. The average objective function values of different levels of the four main parameters of simulated annealing
s N 林分数量Number of management units nrep 林分数量Number of management units r 林分数量Number of management units T 林分数量Number of management units 400 1 600 3 600 6 400 10 000 400 1 600 3 600 6 400 10 000 400 1 600 3 600 6 400 10 000 400 1 600 3 600 6 400 10 000 100 4.8 8.1 17.3 39.2 70.0 100 1.6 4.2 10.4 28.3 47.8 0.700 1.6 4.2 8.7 19.7 32.0 0.001 2.8 12.5 21.6 50.5 61.2 200 7.5 8.2 15.8 36.5 85.0 200 2.9 6.0 12.9 37.4 74.9 0.750 1.8 4.4 9.7 23.0 38.2 0.010 2.8 5.6 19.8 95.4 87.6 300 7.5 8.9 16.8 37.9 70.6 300 4.1 6.1 12.3 27.1 70.8 0.800 2.6 4.2 10.9 26.5 47.6 0.050 3.6 5.8 18.4 79.3 101.8 400 7.2 8.3 17.9 39.7 67.9 400 5.8 6.2 12.8 28.4 83.5 0.850 2.8 4.4 11.6 29.9 60.8 0.100 4.1 8.1 20.2 51.2 99.2 500 8.3 9.9 19.2 35.5 90.5 500 7.9 7.4 17.6 40.3 88.0 0.900 4.1 4.9 15.1 38.0 69.2 0.500 7.2 13.1 17.8 47.0 80.2 600 7.5 9.4 18.4 46.5 69.8 600 7.5 9.4 18.4 46.5 69.8 0.950 7.5 9.4 18.4 46.5 69.8 1.000 7.5 9.4 18.4 46.5 69.8 700 6.7 9.0 19.9 44.6 97.5 700 9.7 10.3 16.4 48.7 108.5 0.975 15.3 13.5 22.4 58.6 108.4 2.000 9.4 12.9 17.3 49.8 86.6 800 7.1 10.7 16.8 49.8 84.6 800 11.2 12.5 17.6 43.5 65.2 0.990 46.0 34.6 57.8 107.9 121.0 3.000 8.4 8.8 21.7 44.0 82.4 900 8.5 9.4 17.1 58.7 96.4 900 11.2 13.6 21.8 45.7 94.1 0.995 100.4 61.1 97.4 223.5 218.1 4.000 9.1 13.0 21.9 42.3 86.5 1 000 7.6 11.3 20.0 50.1 102.7 1 000 11.2 15.5 20.9 45.2 83.1 0.999 370.7 418.8 558.9 1280.0 1094.0 5.000 9.4 13.5 22.1 39.2 93.2 Table 3. The average computational time of different levels of the four main parameters of simulated annealing
-
初始解作为模拟退火算法搜索过程的起点,其质量无疑对整个搜索过程具有重要影响。然而,由于模拟退火算法初始解的产生往往采用随机策略来实现,因此增加初始解数量就成为确保模拟退火算法高起点的重要保障。为此,模拟程序采用蒙特卡洛模拟随机产生N个初始解(表 1),但仅选取其中目标函数值最大的解作为算法优化过程的初始解。模拟结果表明各林分规划期末收获蓄积虽然随着初始解数量N值的增大而呈现不同程度的波动,但其整体上并无明显的变化规律,因此可认为规划问题的目标函数值并不受初始解数量的影响。进一步统计分析发现,各林分内目标函数值的平均变异系数随林分数量的增加而呈明显增加趋势,其从3.71%(林分A)增加到13.99%(林分E)。同时,初始解数量对算法的优化时间也无显著影响,但其平均优化时间同样随着林分数量的增加而增加,其从8.45 s(林分A)增加到102.7 s(林分E)。
理论上,每温度下重复次数(nrep)越高,搜索过程探索整个可行解空间的机会(即搜索次数)也越高,进而可增加算法获得满意解的概率。研究结果表明:对林分A~D,目标函数值首先随着nrep值的增加而缓慢下降,之后虽仍有波动但整体处于稳定状态,因此最大目标函数值均是在nrep=100时获得;而对于林分E,目标函数值则首先随着nrep值的增加而呈缓慢的增加趋势,约在nrep=400时获得最大目标函数值,但之后则随着nrep值的继续增加而略有下降且最终处于相对稳定水平。各林分目标函数值的平均变异系数也整体随着林分数量的增加呈增大趋势,即从4.49% (林分A)增加到10.23% (林分D)。除林分E以外,算法优化时间均随着参数nrep值的增加而呈显著的线性增加趋势,各林分拟合方程的确定系数(R2)则高达0.86以上。
根据模拟退火算法原理可知,当金属温度下降的越慢,则其物质结构越稳定。因此,当算法搜索过程下降的越慢,目标解的质量也会越高。但本研究结果表明冷却速率(r)并不是越慢越好,而是与规划问题的规模显著相关。对林分A而言,目标函数值整体随着降温速率r值的增大而呈线性增加趋势,其拟合方程的确定系数为0.81;对林分B而言,目标函数值首先随着r值的增加而缓慢下降,约在r=0.90时目标函数值最小,但此后随着r值的继续增大而成缓慢增加趋势;但对林分C~E,目标函数值均是随着r值的增加先呈缓慢的增加趋势,而后则呈一定的下降趋势且最终基本处于稳定,3个林分获得最大目标函数值时对应的r值分别为:0.75,0.80和0.85。不同林分间目标函数值平均变异系数的差异明显减小,其中林分A的变异系数最小(4.40%),而林分C的变异系数最大(8.09%),且整体上不再受林分数量的影响。各林分优化时间则均随着降温速率r值的增大而成典型的指数增加趋势,其拟合方程的确定系数介于0.54~0.71之间。
根据Boltzman接受准则可知,初始温度(T)越高,算法接受恶化解的概率也越高,进而算法跳出局域收敛和获得满意解的概率也越高,但本研究结果表明较低的初始温度同样有利于增加目标解的质量,这可能是由于本研究所设置的每温度下重复次数nrep值较高所致。对林分A~D而言,目标函数值首先均随着初始温度T值的增加而呈缓慢下降趋势,此后虽仍有波动但最终会逐渐趋于平稳。4个林分的初始温度T值大致在0.05×106,0.05×106,0.5×106和2×106时达到稳定状态。与每温度下重复次数类似,各林分目标函数值的平均变异系数也表现出随林分数量的增加而增加的趋势,其从4.52%(林分A)增加到10.26%(林分D)。除林分A的优化时间与初始温度T值呈对数增加趋势(R2=0.89)外,其余4个林分的优化时间则均不受T值的影响。
-
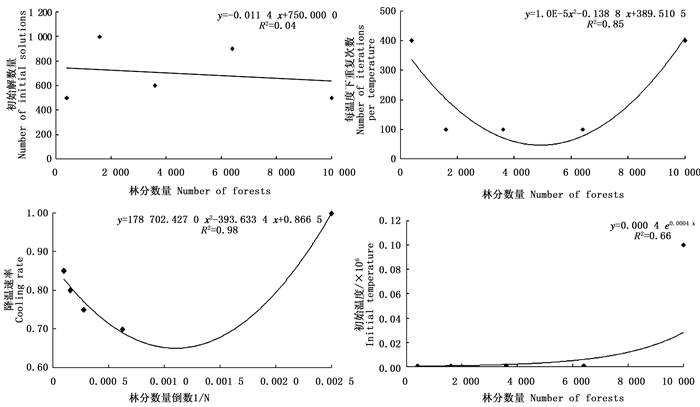
根据上述分析可知,林分数量会显著影响模拟退火算法的优化结果,但因模拟退火算法的邻域产生和新解接受机制均采用随机策略,因此各参数的最优取值在实践中往往会很难确定。本研究仅根据上述模拟结果选取每个数据集中平均目标函数值最大的参数级别作为该参数的最优取值,而不考虑不同参数值对应的目标函数值间的差异是否显著的问题。在此背景下,图 1给出了模拟退火算法各参数最优取值与林分数量的关系曲线。可以看出,初始解数量N整体上不受林分数量的影响,其拟合确定系数R2仅为0.04,但各规划问题的最优初始解数量均在500次模拟以上。对每温度下重复次数nrep而言,当林分数量为400时,nrep值相对较高(400次),但之后随着林分数量的继续增加,nrep值始终维持在100次;而当林分数量再继续增加到10 000时,nrep值则呈快速增加趋势,拟合结果表明两者间呈显著的多项式曲线关系(R2=0.85)。对降温速率r而言,当林分数量为400时,模拟退火算法的降温速率r值相对较慢(0.999);但此后随着林分数量的增加呈缓慢的增加趋势,但进一步统计结果表明降温速率r与林分数量倒数(1/N)间存在显著的多项式曲线关系(R2=0.98)。当林分数量小于6 400时,模拟退火算法的初始温度T值均保持不变(0.001×106);但当林分数量继续增加时,初始温度T值则呈快速增加趋势,其拟合曲线呈显著的指数关系(R2=0.66)。综上所述,可认为模拟退火算法的参数取值对林分数量的变化是敏感的。

Figure 1. Trade-offs between the optimal parameter values of simulated annealing and the size of planning problems
-
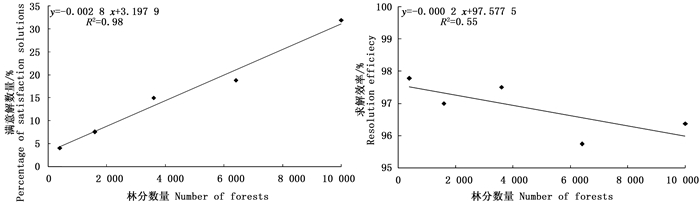
采用式(9)和式(10)、(11)分别计算不同林分中模拟退火算法获得满意解的概率PN和基于最大目标函数值的求解效率RE。统计结果显示,PN和RE值均与林分数量显著相关(图 2),其中PN值随林分数量的增加呈显著地线性增加趋势,其拟合方程的确定系数R2高达0.94,也就是说随着林分数量的增加模拟退火算法获得满意解的概率也会显著增加。对RE值而言,各林分的求解效率均在95%以上,说明模拟退火算法具有较高的求解效率,能充分适应复杂的森林规划问题。此外,虽然模拟退火算法的求解效率在不同林分间表现出一定的波动状态,但整体呈明显的下降趋势,其线性拟合关系的确定系数R2也达到0.50以上。

Figure 2. Trade-offs between the numbers of satisfactions solutions (right), the resolution efficiency (left) of simulated annealing and the size of planning problems
2.1. 参数敏感性
2.2. 最优参数敏感性
2.3. 求解效率敏感性
-
本研究以模拟退火算法为例,以5个不同大小的栅格数据为基础,系统评估模拟退火算法4个主要参数取值、求解效率(即RE值)及获得满意解概率(即PN值)等核心问题随林分数量的变化规律。研究结果表明,当对4 000个目标函数值分别不同参数、不同级别以及不同林分进行统计时,其平均变异系数仅在0.18%~14.95%之间,验证了模拟退火算法优化结果的高度稳定性,这与Bettinger等[16]、Strimbu等[18]、Falcã等[19]以及Pukkala等[20]的研究结果一致,说明模拟退火算法能够满足复杂森林规划问题的需要。
规划问题目标函数值并不一定会随着参数的增大而增大,实际应用中会呈现出多种多样的变化趋势。受热力学原理的启发,传统上认为初始温度越高、降温速率越慢,越有利于算法获得高质量的目标解,但本研究结果显然与其不完全相符,这可能是由于:1)当初始温度很高、降温速率很慢时,根据Metropolis准则算法会大量接受恶化解,这并不完全有利于目标函数值的提升;2)不同学者所研究规划问题的复杂程度、编制算法的执行能力与效率以及测试参数的范围等因素均各不相同。因此,在采用启发式算法解决具体的森林规划问题时应慎重选择各算法的参数值,以确保规划结果的稳定性和可靠性。
最优参数取值与规划问题规模显著相关,但其关系目前还存在较大的不确定性。模拟结果表明:每温度下重复次数和初始温度分别与林分数量存在着显著的多项式(R2=0.85)和指数(R2=0.66)关系,降温速率则与林分数量倒数存在显著多项式关系(R2=0.98),而初始解数量和降温速率则不受林分数量的影响(R2= 0.04),但进一步统计结果表明初始解数量至少维持在500次以上。需要强调的是,无论各参数与林分数量存在何种关系,其均会表现出一定的变异性。显然,本研究所获得的结果与Pukkala等[20]的研究结论并不完全相同,他们建议该算法的初始温度应设为2/N,冷却速率应为1%~2%的初始温度(即0.01×1/N~0.02×1/N),其中N为林分数量。但需要特别指出的是,在他们的研究中每个参数的等级以及模拟的森林数量均仅为5个,且每个森林中的林分(或小班)数量仅为100~800个,因此他们给出的这种关系也缺乏足够的数据支撑。
模拟退火算法求解效率和获得满意解概率也与规划问题规模显著相关。这可理解为:对一个特定的规划问题,当林分数量越多,可行解空间也越大,满意解空间也会增大(根据本文对满意解的定义,即以MIP目标函数值10%以内的解空间),因此若想进一步获得最优解则会变得更为困难。本研究结果表明,模拟退火算法获得满意解的概率会随着林分数量的增加而增加,这与Crowe等的结论一致[4]。但在此基础上,本研究还发现模拟退火算法最优解质量(即RE值)却随着林分数量的增加而显著降低。
需要特别说明的是,虽然栅格模拟数据可避免复杂林分特征和空间关系等因素对规划结果的干扰,从而有利于实施一个精确的控制实验,但其与真实的林分数据仍存在较大差异,包括林分(如立地、密度、树种组成等)和非林分(如面积、空间关系等)因素。在空间方面,董灵波等[26]指出盘古林场2009年二类调查数据中每个林分的相邻林分数量在1~22个范围内,平均数量为5.46个,标准差为1.90个,显然这种复杂的空间关系可能会对本文结论产生一定影响,但其作用程度仍有待于进一步研究。
-
1) 本研究模拟的4 000个目标函数值的平均变异系数仅为0.18%~14.95%,说明模拟退火算法优化结果具有高度稳定性,能够适应复杂森林规划问题的需求;
2) 模拟退火算法参数取值与林分数量密切相关,其中每温度下重复次数和初始温度分别与林分数量呈显著的多项式(R2=0.85)和指数(R2=0.66)关系,而降温速率则与林分数量倒数呈显著的多项式关系(R2=0.98),初始解数量虽不受林分数量影响,但其至少应维持在500次以上;
3) 模拟退火算法求解效率(即RE值)和获得满意解概率(即PN值)同样受林分数量的影响,其中满意解概率随林分数量的增加而呈显著线性增加趋势(R2=0.98),但求解效率则呈显著线性下降趋势(R2=0.55)。
 DownLoad:
DownLoad: